关键交互时序
sequenceDiagram
participant User
participant ASR
participant LLM
participant TTS
User->>ASR: 说话
ASR->>ASR: 实时识别
ASR->>Main: 触发asr_callback
Main->>ASR: 暂停识别
Main->>LLM: 发送问题
LLM->>TTS: 流式返回响应
TTS->>TTS: 合成语音队列
TTS->>Audio: 播放音频
loop 等待播放完成
Main->>TTS: 检查缓冲区状态
TTS-->>Main: 状态反馈
end
Main->>ASR: 恢复识别
大语言模型测试的基本流程
graph TD
A[程序启动] --> B[注册信号处理]
B --> C[初始化PortAudio音频管理]
C --> D[初始化LLM服务器]
D --> E[设置LLM回调函数]
E --> F[初始化ASR模块]
F --> G[设置ASR回调函数]
G --> H[启动ASR录音]
H --> I[进入主循环休眠10分钟]
subgraph 语音识别流程
H --> J[ASR持续采集音频]
J --> K{检测到有效语音?}
K -- 是 --> L[暂停ASR录音]
L --> M[发送文本到LLM服务器]
K -- 否 --> J
end
subgraph LLM处理流程
M --> N[LLM处理请求]
N --> O[处理完成调用llm_server_callback]
O --> P[记录响应内容]
P --> Q[恢复ASR录音]
end
subgraph 信号处理流程
R[用户按下Ctrl+C] --> S[触发signalHandler]
S --> T[停止ASR服务]
T --> U[释放资源]
U --> V[退出程序]
end
I --> R
Q --> J
前言
目前接手了llm大语言模型和语音合成和识别的工作这边需要查看之前编写的代码。
目前需要加入的功能是:
添加方言普通话修正环节:在语音识别将句子发送给大语言模型时先将原始识别句子送给大语言模型进行分析得到标准普通话结果后返回给大语言模型。
对于大语言模型医学问题不专业的问题,我尝试了华佗gpt后我发现还是没有很大的改变,因为医学问题十分的复杂不是三言两句和有限信息可以准确分析的。我这边的构想是涉及到医学专业问题减少类似与多少这样量词的使用,尽量以通识建议的口吻进行,而且一定要声明以医生诊断为准的免责声明。
我需要添加一段对固定内容的宣讲,这是死板的内容难度是不大的应该。
为了实现这些功能我需要学习和接手llm的代码目前看起来问题不算少,祝我好运!
目前运行问题总揽
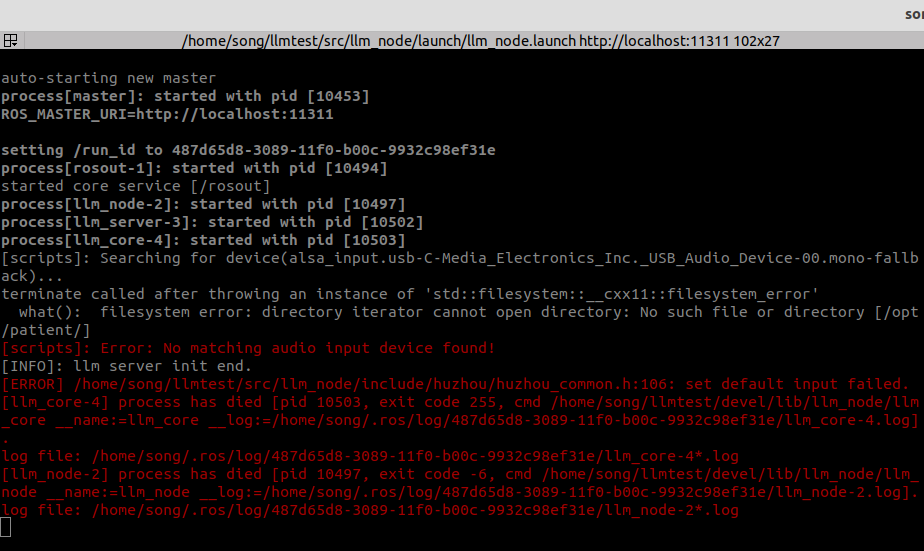
本来想用自己的耳机来进行测试发现这个错误
对deepseek.h的分析
让我来瞅瞅DeepseekServer类里有什么。
其中定义了一个名为 DeepseekServer 的类,继承它自 LlmBase 类
然后定义静态成员变量和函数
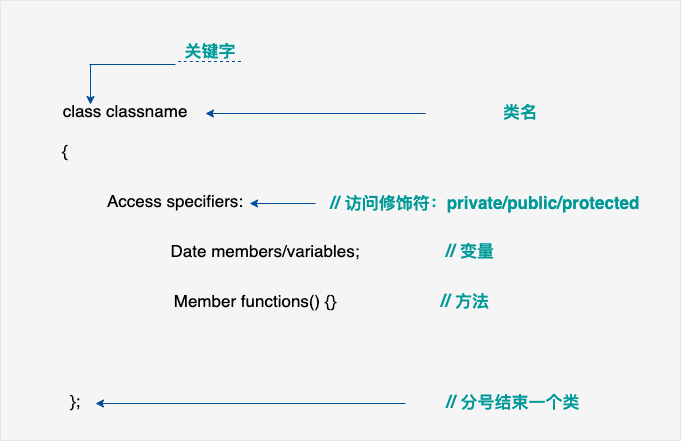
其他都看看的差不多了补充个之前的知识盲点,其中的public:和private:是什么意思有什么作用说实话我还不太明白。
公开和私有
public:
含义:
- public 表示类中的成员是公开的,可以在类的外部被访问。
作用:
- 允许外部代码调用类中的 public 成员函数。
- 允许外部代码直接访问和修改类中的 public 成员变量。
private:
- 含义:
- private 表示类中的成员是私有的,不能在类的外部直接访问。
- 作用
- 隐藏类的内部实现细节,保护成员变量和函数不被外部代码随意访问和修改。
- 实现封装,确保类的内部状态的一致性和完整性,防止外部代码对类的内部机制产生依赖。